Note - These are my notes on DeepLearning Specialization Course for Setting Up Optimisation (Normalization | Vanishing/Exploding Gradients , Weight Initialization , Gradient Checking || Improving Deep Neural Networks
Introduction:
When training a neural network, one of the techniques that will speed up your training is if you normalize your inputs. Let’s see what that means. Let’s see if a training sets with two input features. So the input features x are two dimensional, and here’s a scatter plot of your training set.
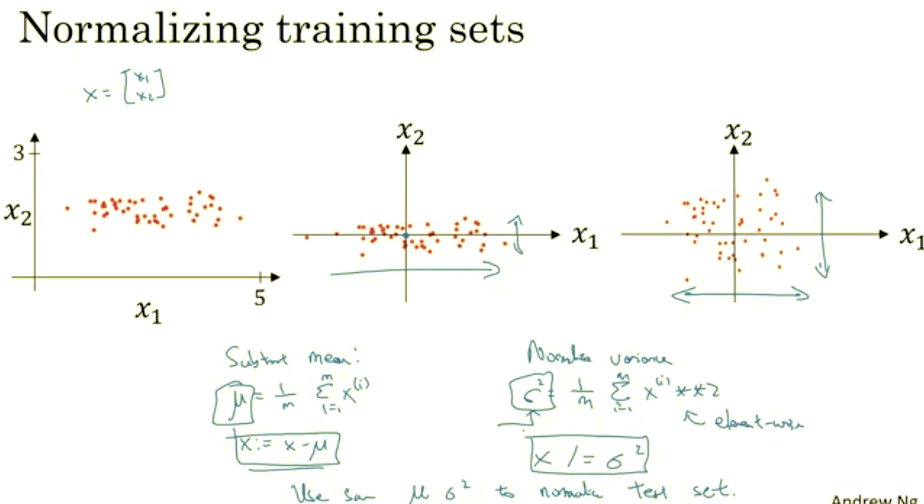
Normalizing your inputs corresponds to two steps. The first is to subtract out or to zero out the mean. So you set mu = 1 over M sum over I of Xi. So this is a vector, and then X gets set as X- mu for every training example, so this means you just move the training set until it has 0 mean. And then the second step is to normalize the variances. So notice here that the feature X1 has a much larger variance than the feature X2 here. So what we do is set sigma = 1 over m sum of Xipower2.
I guess this is a element y squaring. And so now sigma squared is a vector with the variances of each of the features, and notice we’ve already subtracted out the mean, so Xi squared, element y squared is just the variances. And you take each example and divide it by this vector sigma squared. And so in pictures, you end up with this. Where now the variance of X1 and X2 are both equal to one.
And one tip, if you use this to scale your training data, then use the same mu and sigma squared to normalize your test set, right? In particular, you don’t want to normalize the training set and the test set differently. Whatever this value is and whatever this value is, use them in these two formulas so that you scale your test set in exactly the same way, rather than estimating mu and sigma squared separately on your training set and test set. Because you want your data, both training and test examples, to go through the same transformation defined by the same mu and sigma squared calculated on your training data.
So, why do we do Normalization?
Why do we want to normalize the input features? Recall that a cost function is defined as written on the top right. It turns out that if you use unnormalized input features, it’s more likely that your cost function will look like this, it’s a very squished out bowl, very elongated cost function, where the minimum you’re trying to find is maybe over there. But if your features are on very different scales, say the feature X1 ranges from 1 to 1,000, and the feature X2 ranges from 0 to 1, then it turns out that the ratio or the range of values for the parameters w1 and w2 will end up taking on very different values. And so maybe these axes should be w1 and w2, but I’ll plot w and b, then your cost function can be a very elongated bowl like that.
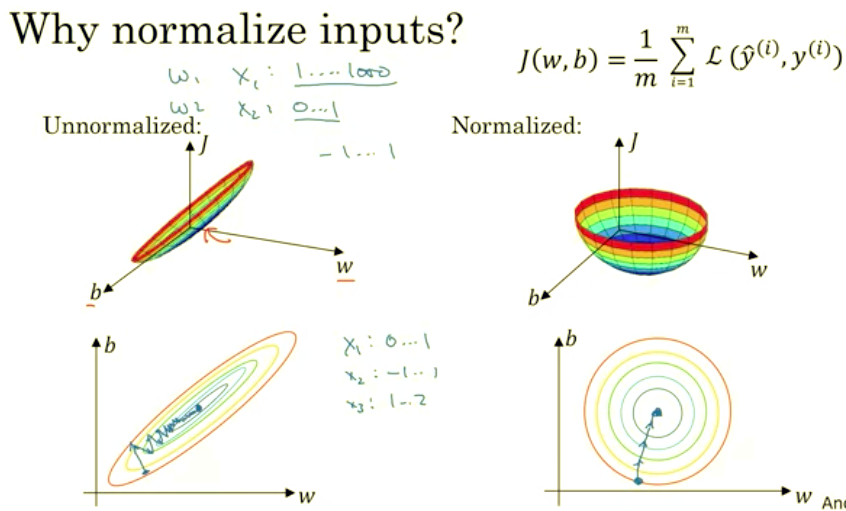
So if you part the contours of this function, you can have a very elongated function like that. Whereas if you normalize the features, then your cost function will on average look more symmetric. And if you’re running gradient descent on the cost function like the one on the left, then you might have to use a very small learning rate because if you’re here that gradient descent might need a lot of steps to oscillate back and forth before it finally finds its way to the minimum. Whereas if you have a more spherical contours, then wherever you start gradient descent can pretty much go straight to the minimum. You can take much larger steps with gradient descent rather than needing to oscillate around like like the picture on the left. Of course in practice w is a high-dimensional vector, and so trying to plot this in 2D doesn’t convey all the intuitions correctly. But the rough intuition that your cost function will be more round and easier to optimize when your features are all on similar scales. Not from one to 1000, zero to one, but mostly from minus one to one or of about similar variances of each other. That just makes your cost function J easier and faster to optimize. In practice if one feature, say X1, ranges from zero to one, and X2 ranges from minus one to one, and X3 ranges from one to two, these are fairly similar ranges, so this will work just fine. It’s when they’re on dramatically different ranges like ones from 1 to a 1000, and the another from 0 to 1, that that really hurts your authorization algorithm. But by just setting all of them to a 0 mean and say, variance 1, like we did in the last slide, that just guarantees that all your features on a similar scale and will usually help your learning algorithm run faster. So, if your input features came from very different scales, maybe some features are from 0 to 1, some from 1 to 1,000, then it’s important to normalize your features. If your features came in on similar scales, then this step is less important. Although performing this type of normalization pretty much never does any harm, so I’ll often do it anyway if I’m not sure whether or not it will help with speeding up training for your algebra.
So that’s it for normalizing your input features. Next, let’s keep talking about ways to speed up the training of your new network.
When training a neural network, one of the techniques
Vanishing / Exploding gradients
One of the problems of training neural network, especially very deep neural networks, is data vanishing and exploding gradients. What that means is that when you’re training a very deep network your derivatives or your slopes can sometimes get either very, very big or very, very small, maybe even exponentially small, and this makes training difficult. In this Topic you see what this problem of exploding and vanishing gradients really means, as well as how you can use careful choices of the random weight initialization to significantly reduce this problem. Unless you’re training a very deep neural network like this, to save space on the slide, I’ve drawn it as if you have only two hidden units per layer, but it could be more as well. But this neural network will have parameters W1, W2, W3 and so on up to WL.
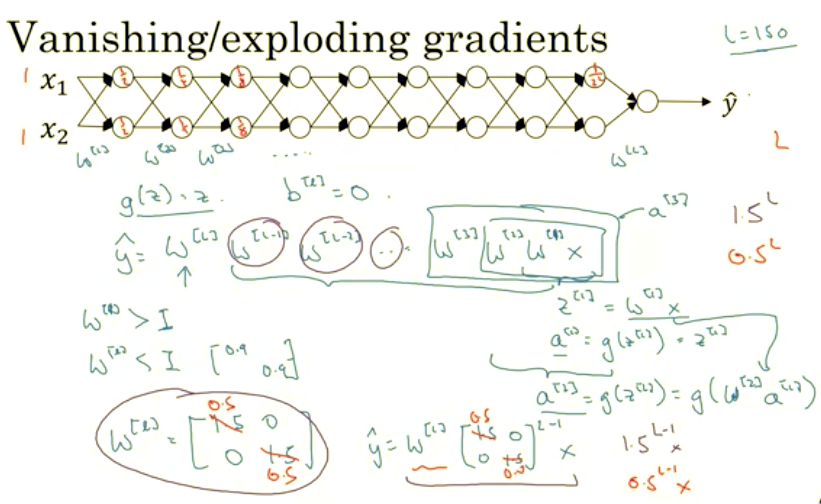
For the sake of simplicity, let’s say we’re using an activation function G of Z equals Z, so linear activation function. And let’s ignore B, let’s say B of L equals zero. So in that case you can show that the output Y will be WL times WL minus one times WL minus two, dot, dot, dot down to the W3, W2, W1 times X. But if you want to just check my math, W1 times X is going to be Z1, because B is equal to zero. So Z1 is equal to, I guess, W1 times X and then plus B which is zero. But then A1 is equal to G of Z1.
But because we use linear activation function, this is just equal to Z1. So this first term W1X is equal to A1. And then by the reasoning you can figure out that W2 times W1 times X is equal to A2, because that’s going to be G of Z2, is going to be G of W2 times A1 which you can plug that in here. So this thing is going to be equal to A2, and then this thing is going to be A3 and so on until the protocol of all these matrices gives you Y-hat, not Y. Now, let’s say that each of you weight matrices WL is just a little bit larger than one times the identity. So it’s 1.5_1.5_0_0.
Technically, the last one has different dimensions so maybe this is just the rest of these weight matrices. Then Y-hat will be, ignoring this last one with different dimension, this 1.5_0_0_1.5 matrix to the power of L minus 1 times X, because we assume that each one of these matrices is equal to this thing. It’s really 1.5 times the identity matrix, then you end up with this calculation. And so Y-hat will be essentially 1.5 to the power of L, to the power of L minus 1 times X, and if L was large for very deep neural network, Y-hat will be very large. In fact, it just grows exponentially, it grows like 1.5 to the number of layers. And so if you have a very deep neural network, the value of Y will explode. Now, conversely, if we replace this with 0.5, so something less than 1, then this becomes 0.5 to the power of L. This matrix becomes 0.5 to the L minus one times X, again ignoring WL. And so each of your matrices are less than 1, then let’s say X1, X2 were one one, then the activations will be one half, one half, one fourth, one fourth, one eighth, one eighth, and so on until this becomes one over two to the L. So the activation values will decrease exponentially as a function of the def, as a function of the number of layers L of the network. So in the very deep network, the activations end up decreasing exponentially.
So the intuition I hope you can take away from this is that at the weights W, if they’re all just a little bit bigger than one or just a little bit bigger than the identity matrix, then with a very deep network the activations can explode. And if W is just a little bit less than identity. So this maybe here’s 0.9, 0.9, then you have a very deep network, the activations will decrease exponentially. And even though I went through this argument in terms of activations increasing or decreasing exponentially as a function of L, a similar argument can be used to show that the derivatives or the gradients the computer is going to send will also increase exponentially or decrease exponentially as a function of the number of layers. With some of the modern neural networks, L equals 150.
Microsoft recently got great results with 152 layer neural network. But with such a deep neural network, if your activations or gradients increase or decrease exponentially as a function of L, then these values could get really big or really small. And this makes training difficult, especially if your gradients are exponentially smaller than L, then gradient descent will take tiny little steps. It will take a long time for gradient descent to learn anything. To summarize, you’ve seen how deep networks suffer from the problems of vanishing or exploding gradients. In fact, for a long time this problem was a huge barrier to training deep neural networks.
It turns out there’s a partial solution that doesn’t completely solve this problem but it helps a lot which is careful choice of how you initialize the weights. To see that, let’s go to the next Topic.
One of the problems of training neural network, especially very deep neural networks, is data vanishing. What that means is that when you’re training a very deep network your derivatives or your slopes can sometimes get either very, very big or very, very small, maybe even exponentially small, and this makes training difficult. In this Topic you see what this problem of exploding and vanishing gradients really means, as well as how you can use careful choices of the random weight initialization to significantly reduce this problem. Unless you’re training a very deep neural network like this, to save space on the slide, I’ve drawn it as if you have only two hidden units per layer, but it could be more as well. But this neural network will have parameters W1, W2, W3 and so on up to WL.
But because we use linear activation function, this is just equal to Z1. So this first term W1X is equal to A1. And then by the reasoning you can figure out that W2 times W1 times X is equal to A2, because that’s going to be G of Z2, is going to be G of W2 times A1 which you can plug that in here. So this thing is going to be equal to A2, and then this thing is going to be A3 and so on until the protocol of all these matrices gives you Y-hat, not Y. Now, let’s say that each of you weight matrices WL is just a little bit larger than one times the identity. So it’s 1.5_1.5_0_0.
Technically, the last one has different dimensions so maybe this is just the rest of these weight matrices. Then Y-hat will be, ignoring this last one with different dimension, this 1.5_0_0_1.5 matrix to the power of L minus 1 times X, because we assume that each one of these matrices is equal to this thing. It’s really 1.5 times the identity matrix, then you end up with this calculation. And so Y-hat will be essentially 1.5 to the power of L, to the power of L minus 1 times X, and if L was large for very deep neural network, Y-hat will be very large. In fact, it just grows exponentially, it grows like 1.5 to the number of layers. And so if you have a very deep neural network, the value of Y will explode. Now, conversely, if we replace this with 0.5, so something less than 1, then this becomes 0.5 to the power of L. This matrix becomes 0.5 to the L minus one times X, again ignoring WL. And so each of your matrices are less than 1, then let’s say X1, X2 were one one, then the activations will be one half, one half, one fourth, one fourth, one eighth, one eighth, and so on until this becomes one over two to the L. So the activation values will decrease exponentially as a function of the def, as a function of the number of layers L of the network. So in the very deep network, the activations end up decreasing exponentially.
_3>Weight Initialization for Deep Networks_3>
In the last paragraph you saw how very deep neural networks can have the problems of vanishing and exploding gradients. It turns out that a partial solution to this, doesn’t solve it entirely but helps a lot, is better or more careful choice of the random initialization for your neural network.
_4>Single Neuron_4>
To understand this, let’s start with the example of initializing the ways for a single neuron, and then we’re go on to generalize this to a deep network. Let’s go through this with an example with just a single neuron, and then we’ll talk about the deep net later. So with a single neuron, you might input four features, x1 through x4, and then you have some a=g(z) and then it outputs some y. And later on for a deeper net, you know these inputs will be right, some layer a(l), but for now let’s just call this x for now.

_4>Numerical approximation of gradients_4>
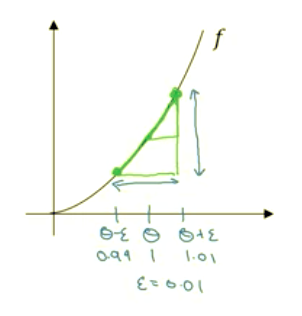
When you implement back propagation you’ll find that there’s a test called creating checking that can really help you make sure that your implementation of back prop is correct. Because sometimes you write all these equations and you’re just not 100% sure if you’ve got all the details right and internal back propagation. So in order to build up to gradient and checking, let’s first talk about how to numerically approximate computations of gradients and in the next Topic, we’ll talk about how you can implement gradient checking to make sure the implementation of backdrop is correct. So lets take the function f and replot it here and remember this is f of theta equals theta cubed, and let’s again start off to some value of theta. Let’s say theta equals 1. Now instead of just nudging theta to the right to get theta plus epsilon, we’re going to nudge it to the right and nudge it to the left to get theta minus epsilon, as was theta plus epsilon. So this is 1, this is 1.01, this is 0.99 where, again, epsilon is same as before, it is 0.01.
It turns out that rather than taking this little triangle and computing the height over the width, you can get a much better estimate of the gradient if you take this point, f of theta minus epsilon and this point, and you instead compute the height over width of this bigger triangle. So for technical reasons which I won’t go into, the height over width of this bigger green triangle gives you a much better approximation to the derivative at theta. And you saw it yourself, taking just this lower triangle in the upper right is as if you have two triangles, right? This one on the upper right and this one on the lower left. And you’re kind of taking both of them into account by using this bigger green triangle. So rather than a one sided difference, you’re taking a two sided difference.