Diffusion Models: Architecture and Theory Behind Modern Generative AI
Diffusion Models represent one of the most important breakthroughs in modern generative artificial intelligence. These models power many advanced image generation systems including tools capable of creating photorealistic artwork, illustrations, and synthetic data. Unlike traditional generative models such as GANs, diffusion models learn to generate data by gradually reversing a noise corruption process. Instead of directly producing images from random vectors, diffusion models start with pure noise and iteratively refine it until a meaningful image emerges. This article provides a detailed explanation of diffusion models including their mathematical foundations, training procedure, architecture design, and modern research developments.
1. Motivation Behind Diffusion Models
Generative models aim to learn the probability distribution of data so that new samples can be generated. Traditional approaches such as Generative Adversarial Networks (GANs) achieved impressive results but often suffer from instability during training. Diffusion models were introduced as a more stable alternative that models the generative process through a sequence of small denoising steps. Instead of learning a complex transformation directly, the model learns to remove small amounts of noise from data.

The generation process can therefore be interpreted as gradually converting random noise into structured data.
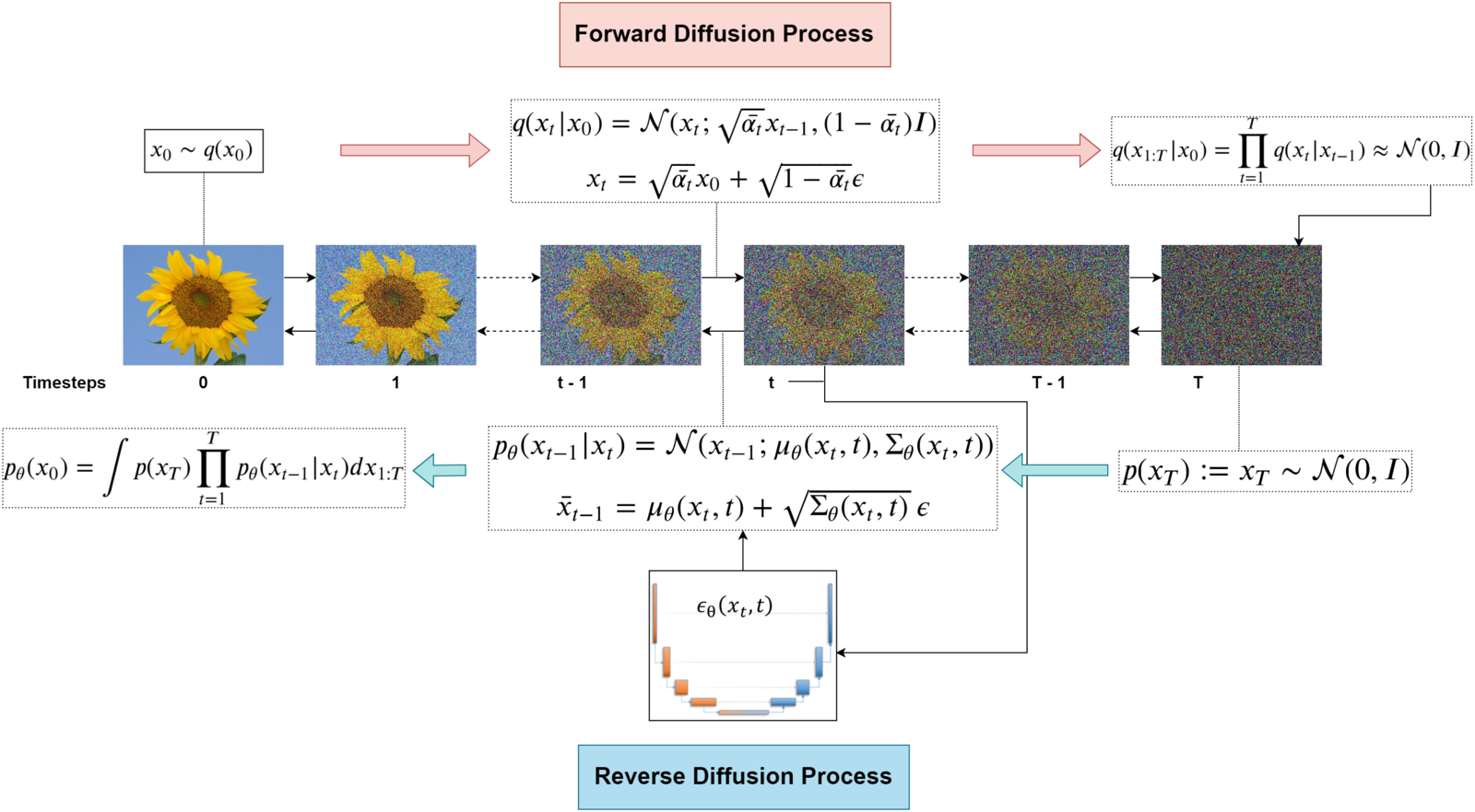
2. Forward Diffusion Process
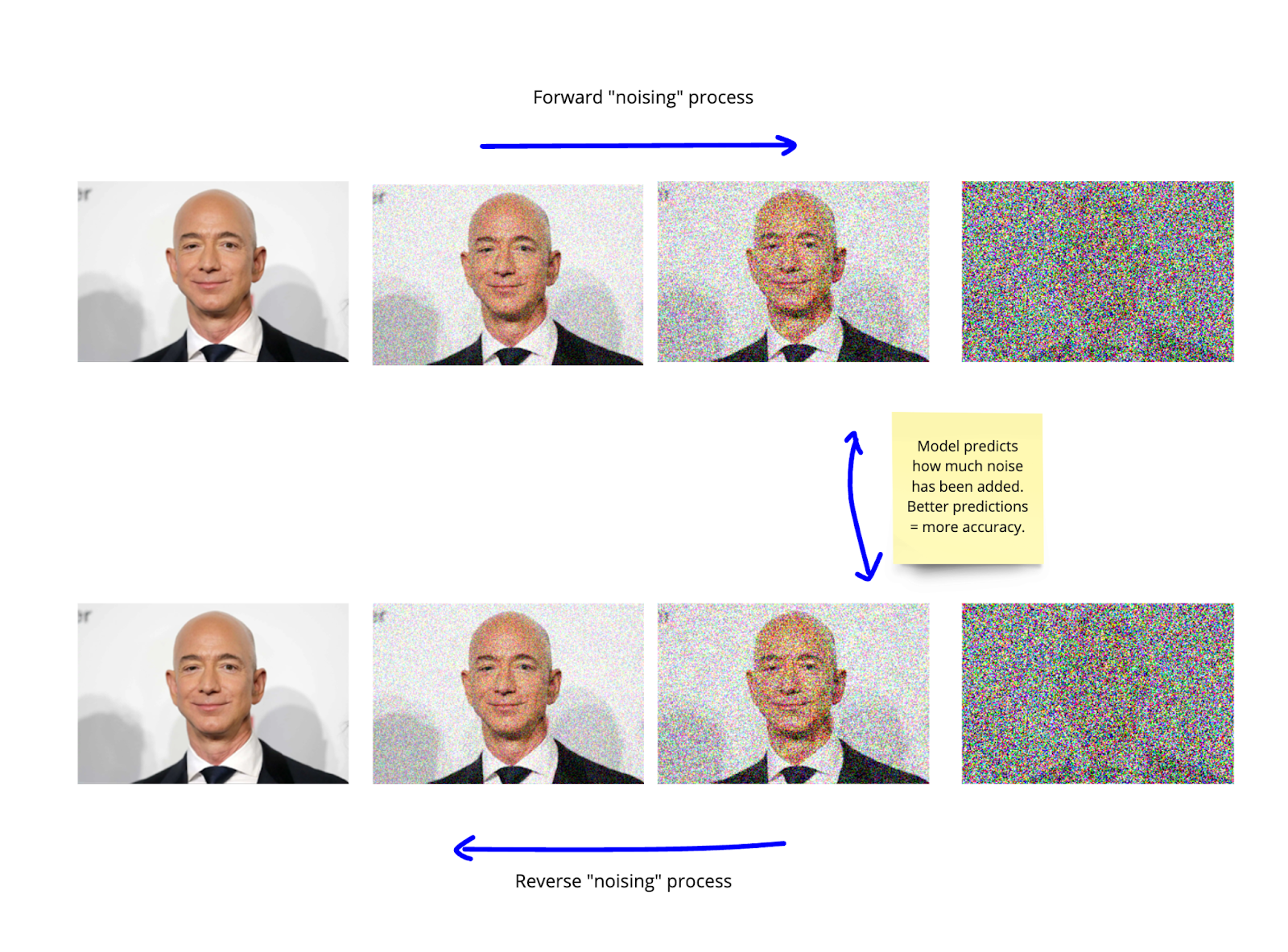
The forward process gradually adds noise to an input image over multiple steps. At each timestep, a small amount of Gaussian noise is added to the data. After many steps, the original image becomes indistinguishable from random noise.
q(x_t | x_{t-1}) = N(x_t ; sqrt(1 - beta_t) x_{t-1}, beta_t I)
Here:
- x0 represents the original data
- xt represents the noisy sample at time step t
- βt controls the amount of noise added

Eventually, the data distribution becomes nearly identical to a Gaussian distribution.
3. Reverse Diffusion Process
The core learning task is to reverse the noise process. The model learns how to progressively remove noise from a sample.
p_theta(x_{t-1} | x_t)
During generation, the model starts with pure noise and repeatedly applies the learned denoising function until a clean image appears.

This reverse process effectively reconstructs realistic data from random noise.
4. Model Architecture
Most modern diffusion models use a neural network architecture based on U-Net. The network receives:
- a noisy image
- a timestep embedding
- optional conditioning information
The model predicts the noise component present in the image.
Key architectural components include:
- Residual convolutional blocks
- Attention layers
- Timestep embeddings
- Skip connections
5. Training Objective
Training diffusion models involves teaching the network to predict the noise added at each step.
L = E || epsilon - epsilon_theta(x_t , t) ||^2
Where:
- ε represents the true noise
- εθ represents the predicted noise
Minimizing this objective allows the model to learn the reverse diffusion process.
6. Sampling Procedure
Image generation begins with a random noise sample. The model then performs hundreds of iterative denoising steps.
- Sample noise vector xT
- Predict noise using the neural network
- Remove predicted noise
- Repeat until t = 0
The final output becomes a realistic synthetic image.
7. Example PyTorch Implementation
import torch
import torch.nn as nn
class SimpleDiffusionModel(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(3,64,3,padding=1),
nn.ReLU(),
nn.Conv2d(64,64,3,padding=1),
nn.ReLU(),
nn.Conv2d(64,3,3,padding=1)
)
def forward(self,x):
return self.net(x)
model = SimpleDiffusionModel()
This simplified example demonstrates the structure of a neural network that predicts noise in a diffusion process.
8. Conditional Diffusion Models
Diffusion models can be conditioned on external information such as text, class labels, or images.
For example, text-to-image models combine diffusion models with large language embeddings.

The model generates images consistent with the provided prompt.
9. Applications
- Text-to-image generation
- Image editing and inpainting
- Video generation
- Audio synthesis
- Scientific data simulation
These capabilities have transformed creative and research workflows across multiple domains.
10. Advantages of Diffusion Models
- Highly stable training
- High-quality image generation
- Flexible conditioning mechanisms
- Scalable architecture
Compared with GANs, diffusion models tend to produce more diverse and consistent results.
11. Key Research Papers
- Denoising Diffusion Probabilistic Models (Ho et al.)
- Improved Denoising Diffusion Models
- Score-Based Generative Modeling
- Latent Diffusion Models
These works form the theoretical foundation for modern diffusion systems.
12. Future Directions
Research in diffusion models is evolving rapidly. Potential future developments include:
- Faster sampling algorithms
- Video diffusion architectures
- 3D generative models
- Multimodal diffusion systems
These innovations may significantly expand the capabilities of generative AI systems.
Conclusion
Diffusion models represent a powerful framework for generative modeling. By learning to reverse a noise process, these models can produce highly realistic synthetic data across multiple modalities. As research continues, diffusion-based architectures are likely to remain a central component of next-generation generative AI systems.