Retrieval Augmented Generation (RAG): Improving Accuracy of Large Language Models
Retrieval Augmented Generation (RAG) is a powerful architecture that combines large language models with external knowledge retrieval systems. While traditional language models rely solely on information learned during training, RAG systems dynamically retrieve relevant documents during inference. This hybrid approach allows models to produce responses that are more accurate, up-to-date, and grounded in factual information. RAG architectures have become a central component of modern AI systems, particularly in enterprise search, question answering, and knowledge assistant platforms.
1. Why Retrieval is Needed
Although large language models possess impressive capabilities, they suffer from several limitations:
- Knowledge is frozen at training time
- Models may hallucinate incorrect information
- Training data cannot easily be updated
- Large models cannot store all world knowledge
Retrieval Augmented Generation addresses these problems by allowing the model to access external knowledge sources such as document databases, websites, or enterprise knowledge bases.
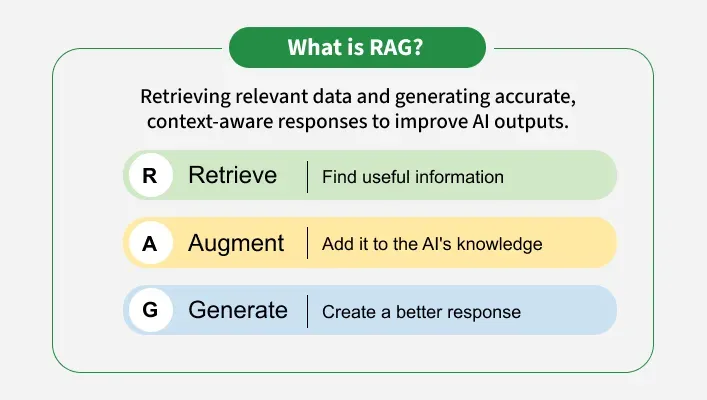
2. Core Idea Behind RAG
The central idea behind RAG is simple: instead of relying entirely on internal parameters, the model retrieves relevant documents from an external database and incorporates them into the generation process.
A typical workflow involves three stages:
- User query is converted into an embedding vector
- Relevant documents are retrieved from a vector database
- The language model generates an answer using retrieved context
This architecture significantly improves the reliability of model outputs.
3. Embedding Models
Before documents can be retrieved efficiently, they must be transformed into numerical vector representations called embeddings. These vectors capture semantic meaning of text so that similar concepts are located close together in vector space.
embedding = model.encode(document)
Embeddings enable efficient similarity search across millions of documents.
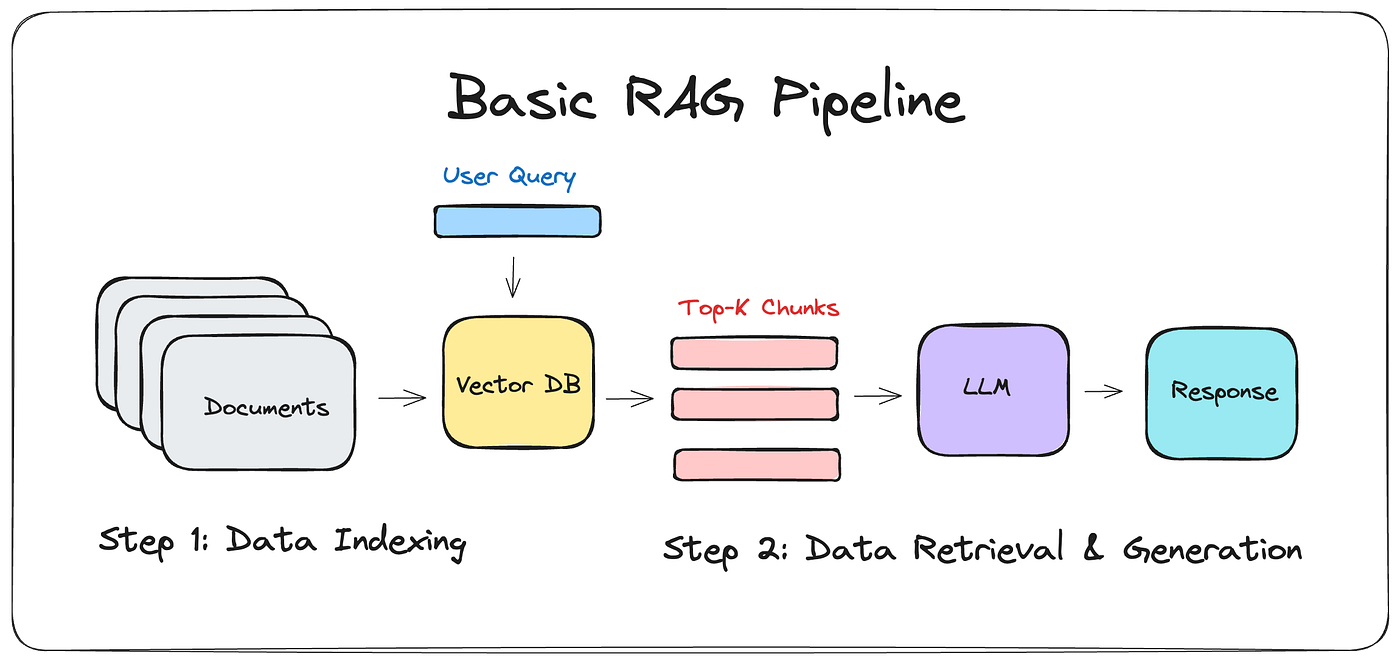
4. Vector Databases
Vector databases are specialized storage systems designed to efficiently search high-dimensional embedding vectors.
Popular vector search techniques include:
- Approximate nearest neighbor search
- Hierarchical navigable small world graphs (HNSW)
- Product quantization
These techniques allow real-time retrieval even for datasets containing millions or billions of vectors.
5. Retrieval Step
When a user submits a question, the query is converted into an embedding vector. The system then finds the most similar vectors stored in the database.
similar_docs = vector_db.search(query_embedding)
The retrieved documents become context for the language model.
6. Augmented Generation
After retrieval, the system combines the query and retrieved documents into a prompt. The language model then generates an answer grounded in that context.
prompt = query + retrieved_documents response = LLM(prompt)
This ensures the response is based on real documents rather than purely model memory.

7. Example Pipeline
A simplified RAG pipeline might look like the following:
documents -> chunking
-> embeddings
-> vector database
user query -> embedding
-> vector search
-> retrieved context
-> language model
-> generated answer
This modular design allows each component to be improved independently.
8. Benefits of RAG
- Reduces hallucinations
- Provides up-to-date knowledge
- Improves factual accuracy
- Allows integration with private datasets
- Reduces need for frequent model retraining
9. Enterprise Applications
Retrieval augmented generation is widely used across industries.
- Enterprise document search
- Customer support assistants
- Legal document analysis
- Medical knowledge assistants
- Research tools
Organizations can build domain-specific AI systems by connecting LLMs to their internal knowledge repositories.
10. Example Python Pseudocode
query = "What is retrieval augmented generation?" query_embedding = embed_model.encode(query) docs = vector_db.search(query_embedding) context = concatenate(docs) response = llm.generate(query + context) print(response)
This simplified example illustrates how retrieval and generation components work together.
11. Challenges
Despite its advantages, RAG systems still face several challenges.
- Retrieval quality heavily affects performance
- Context window limitations
- Latency from database queries
- Chunking strategy complexity
12. Future Developments
Research in retrieval augmented generation is progressing rapidly. Future improvements may include:
- Adaptive retrieval mechanisms
- Long context transformer models
- Hybrid search systems
- Self-updating knowledge bases
These innovations will make AI systems more reliable and capable of handling real-world knowledge tasks.
Conclusion
Retrieval Augmented Generation represents a major step toward building trustworthy and scalable AI systems. By combining large language models with powerful retrieval mechanisms, RAG systems provide accurate, context-aware responses grounded in real knowledge sources. As AI continues to evolve, RAG architectures will likely remain a key building block for intelligent assistants and enterprise AI platforms.