Understanding Large Language Models (LLMs): Architecture, Training and Applications
Introduction
Large Language Models (LLMs) represent one of the most significant advancements in artificial intelligence and natural language processing. These models are capable of understanding, generating, and reasoning over human language with remarkable accuracy. LLMs are trained on massive datasets containing books, research papers, websites, and other textual information. By learning statistical patterns within this data, they develop the ability to perform a wide range of tasks such as text generation, translation, summarization, and coding assistance.

What Are Large Language Models?
A Large Language Model is a deep neural network designed to predict the probability distribution of sequences of words. Given a sequence of tokens, the model predicts the most likely next token.
P(w_t | w_1 , w_2 , ... , w_{t-1})
Through this simple objective, the model gradually learns grammar, semantics, factual knowledge, and reasoning abilities.
Transformer Architecture
Most modern LLMs are based on the Transformer architecture introduced in the landmark paper "Attention Is All You Need". Transformers replace recurrent neural networks with attention mechanisms that allow models to process entire sequences simultaneously.
Key components include:
- Token embeddings
- Positional encodings
- Self-attention layers
- Feedforward neural networks
- Layer normalization

Self-Attention Mechanism
Self-attention enables each word in a sentence to focus on other relevant words while processing. For example, in the sentence:
"The animal didn't cross the street because it was too tired."
The model learns that the word "it" refers to "animal".
Mathematically, attention is computed using query, key, and value vectors.
Attention(Q,K,V) = softmax(QK^T / sqrt(d_k)) V
Training Large Language Models
Training an LLM involves several stages.
1. Pretraining
The model is trained on massive unlabeled text datasets using next-token prediction.
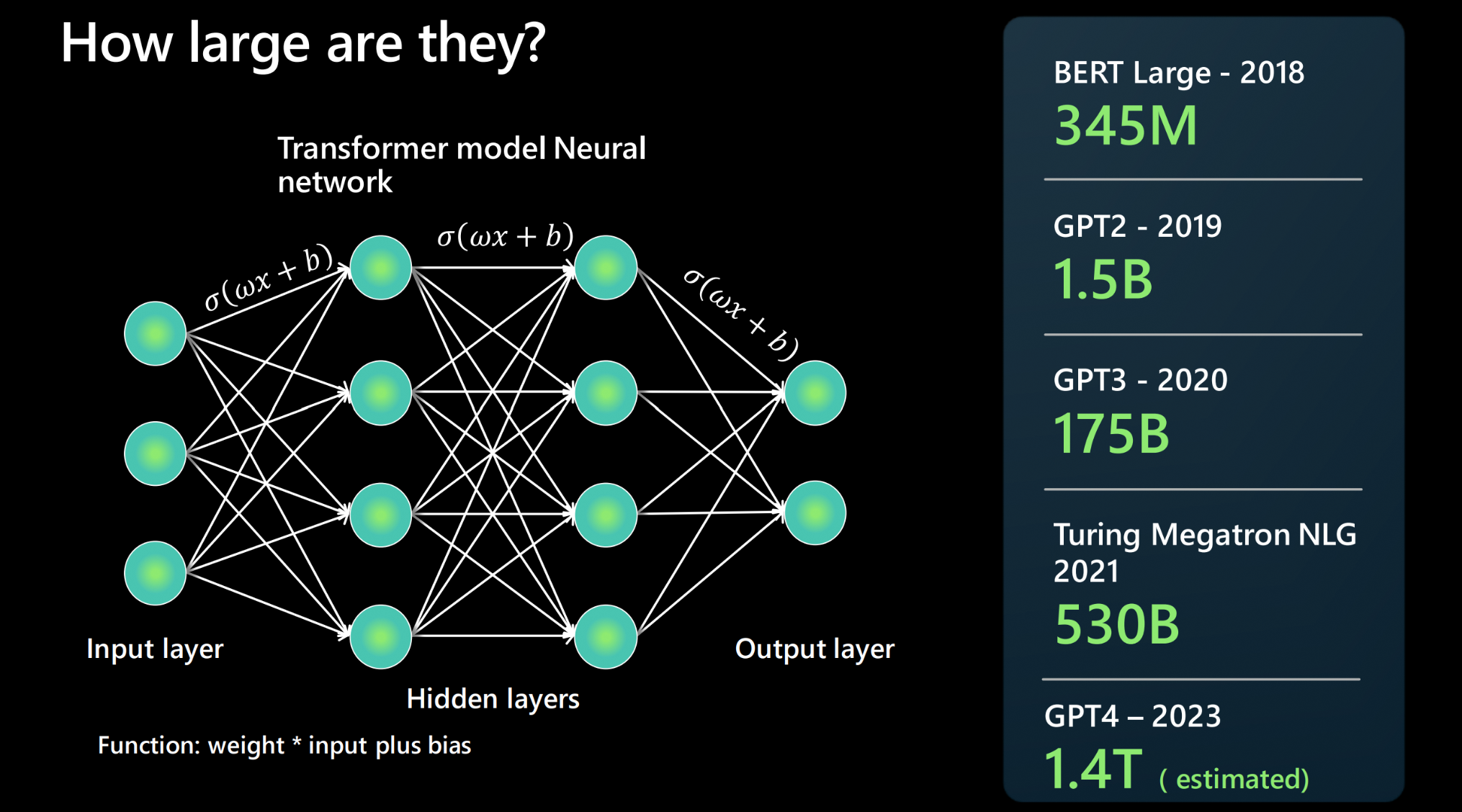
2. Fine-tuning
After pretraining, the model is refined using curated datasets for specific tasks such as dialogue or code generation.
3. Alignment
Modern systems use Reinforcement Learning from Human Feedback (RLHF) to align model responses with human preferences.
Scaling Laws
One of the most important discoveries in modern AI is that model performance improves predictably with scale. Increasing:
- Model parameters
- Training data
- Compute resources
leads to significant improvements in performance.
Applications of LLMs
- Conversational AI
- Automated coding assistance
- Document summarization
- Language translation
- Research assistance
- Content generation
LLMs are now integrated into many software platforms and enterprise applications.
Example PyTorch Implementation
import torch
import torch.nn as nn
class TinyLanguageModel(nn.Module):
def __init__(self,vocab_size,hidden):
super().__init__()
self.embedding = nn.Embedding(vocab_size,hidden)
self.linear = nn.Linear(hidden,vocab_size)
def forward(self,x):
x = self.embedding(x)
x = self.linear(x)
return x
model = TinyLanguageModel(50000,512)
Limitations
- High computational cost
- Potential hallucinations
- Bias in training data
- Large memory requirements
Future of LLMs
Research is actively exploring improvements including:
- Multimodal models combining text, images, and video
- Efficient training techniques
- Long-context reasoning
- Autonomous AI agents
These developments will further expand the capabilities of large language models across science, engineering, and industry.
Conclusion
Large Language Models have fundamentally transformed natural language processing. Their ability to understand and generate human language makes them one of the most powerful tools in modern artificial intelligence. As models continue to scale and new training techniques emerge, LLMs will likely play a central role in the next generation of intelligent systems.