Vector Databases: The Backbone of Modern AI Search Systems
Vector databases have become a crucial component in modern artificial intelligence systems, especially those involving large language models, semantic search, and recommendation systems. Unlike traditional databases that store structured rows and columns, vector databases are designed to store and search high-dimensional vectors. These vectors represent the semantic meaning of text, images, audio, or other types of data. As AI systems increasingly rely on embeddings to understand meaning, vector databases provide the infrastructure required to perform fast and accurate similarity searches across massive datasets.
1. What Are Embeddings?
Embeddings are numerical representations of data created by machine learning models. They transform text, images, or other content into vectors in high-dimensional space.
For example, the sentences:
“Machine learning is fascinating.” “Artificial intelligence is interesting.”
will produce vectors that are very close to each other in vector space because their meanings are similar.
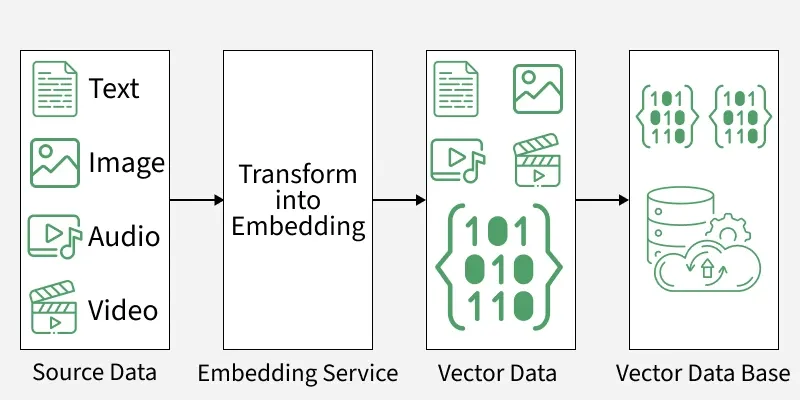
This allows computers to compare meaning rather than just exact keywords.
2. Why Traditional Databases Are Not Enough
Traditional relational databases are optimized for structured queries such as:
SELECT * FROM documents WHERE title = "AI Research"
However, semantic queries such as:
“Find documents related to deep learning breakthroughs”
require similarity search rather than exact matching.
Vector databases solve this problem by performing nearest-neighbor searches across embedding vectors.
3. Similarity Search
The core operation in vector databases is similarity search. When a query vector is provided, the system finds vectors that are closest to it in the vector space.
Common similarity metrics include:
- Cosine similarity
- Euclidean distance
- Dot product similarity
similarity(q, d) = (q · d) / (||q|| ||d||)
Higher similarity values indicate more semantically related content.
4. Approximate Nearest Neighbor Algorithms
Searching through millions of vectors can be computationally expensive. To solve this problem, vector databases use approximate nearest neighbor (ANN) algorithms.
These algorithms trade a small amount of accuracy for massive performance improvements.
- HNSW (Hierarchical Navigable Small World graphs)
- IVF (Inverted File Index)
- Product Quantization
These methods allow similarity searches to be performed in milliseconds even across extremely large datasets.
5. Architecture of a Vector Database
A typical vector database system includes several components.
- Embedding generation model
- Vector storage engine
- Indexing structure
- Query processing layer
- Similarity ranking system
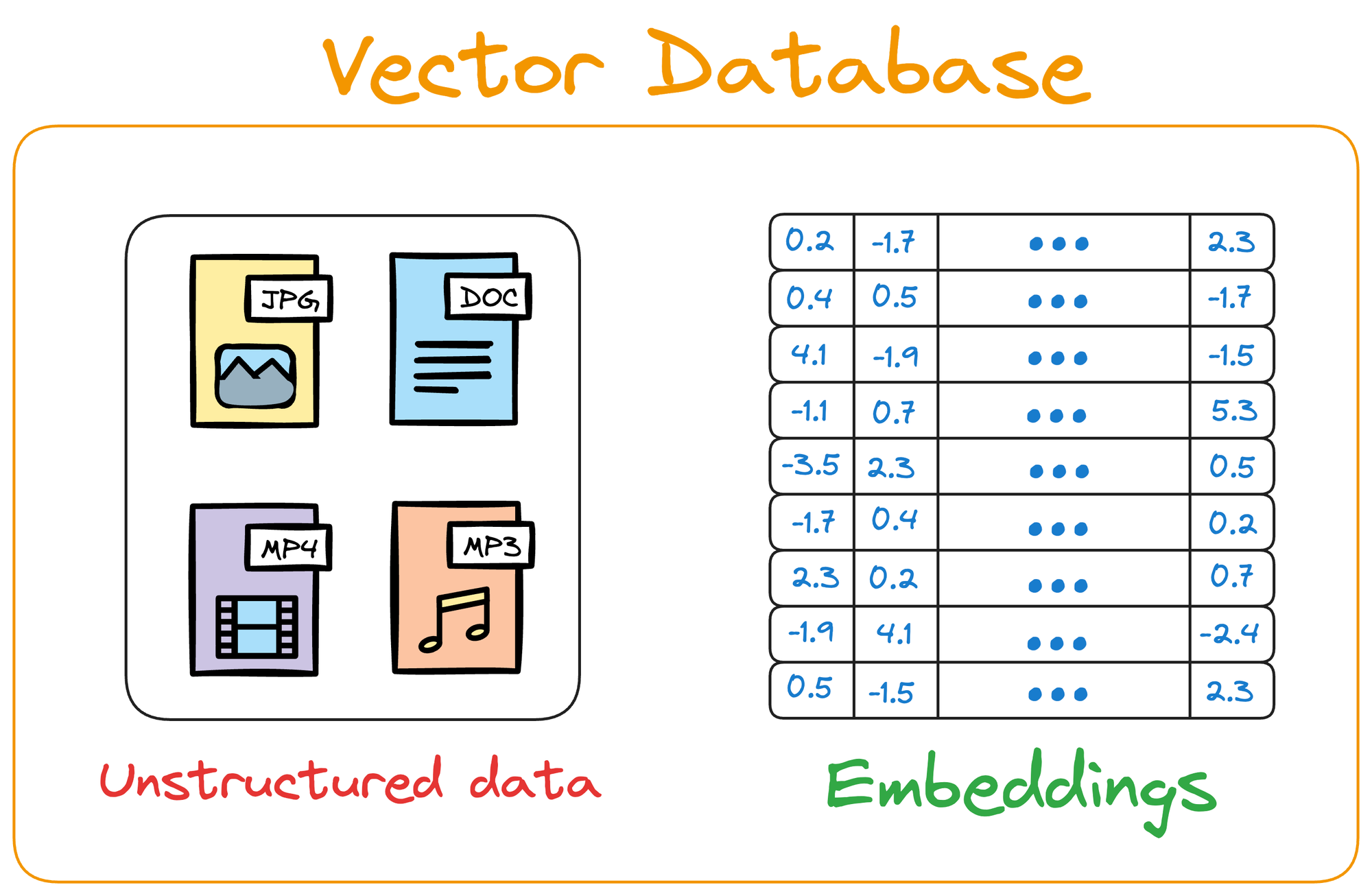
Together these components allow efficient storage and retrieval of semantic data.
6. Role in AI Systems
Vector databases are heavily used in modern AI architectures.
One of the most common applications is retrieval augmented generation (RAG), where relevant documents are retrieved before generating responses with a language model.
This improves the factual accuracy of AI systems by grounding responses in external knowledge sources.
7. Example Workflow
A typical AI pipeline using vector databases might look like this:
documents ↓ text chunking ↓ embedding model ↓ vector database storage user query ↓ query embedding ↓ vector search ↓ retrieve top documents ↓ LLM generates response
This workflow enables powerful knowledge retrieval systems.
8. Real-World Applications
- Semantic search engines
- AI chatbots with knowledge bases
- Recommendation systems
- Fraud detection systems
- Multimedia search (image/audio/video)
Many modern AI products rely on vector databases to deliver fast and intelligent search capabilities.
9. Example Python Pseudocode
query = "machine learning models"
query_vector = embed_model.encode(query)
results = vector_database.search(query_vector, top_k=5)
for r in results:
print(r.document)
This simplified example demonstrates how a semantic search query is processed using embeddings and vector similarity.
10. Challenges
Although vector databases offer powerful capabilities, they also introduce new challenges.
- High memory requirements
- Complex indexing algorithms
- Embedding quality dependency
- Handling very large datasets
Proper system design is necessary to achieve optimal performance.
11. Future of Vector Databases
As AI systems continue to grow, vector databases are expected to become even more important. Future innovations may include:
- Hybrid search combining keyword and vector search
- Distributed vector indexing
- Multimodal embedding support
- Real-time vector updates
These advancements will enable scalable AI systems capable of managing massive knowledge repositories.
Conclusion
Vector databases provide the infrastructure required for semantic search in modern artificial intelligence systems. By storing and indexing high-dimensional embeddings, these databases allow machines to understand relationships between pieces of information at a deeper level. As the use of large language models and AI assistants continues to grow, vector databases will remain a fundamental technology enabling intelligent search and knowledge retrieval.