- Random Forest Intution
- Why Random Forest
- Implementation Random Forest with social network database
- Please Click Here to download the dataset used for this example
What is Random Forest ?
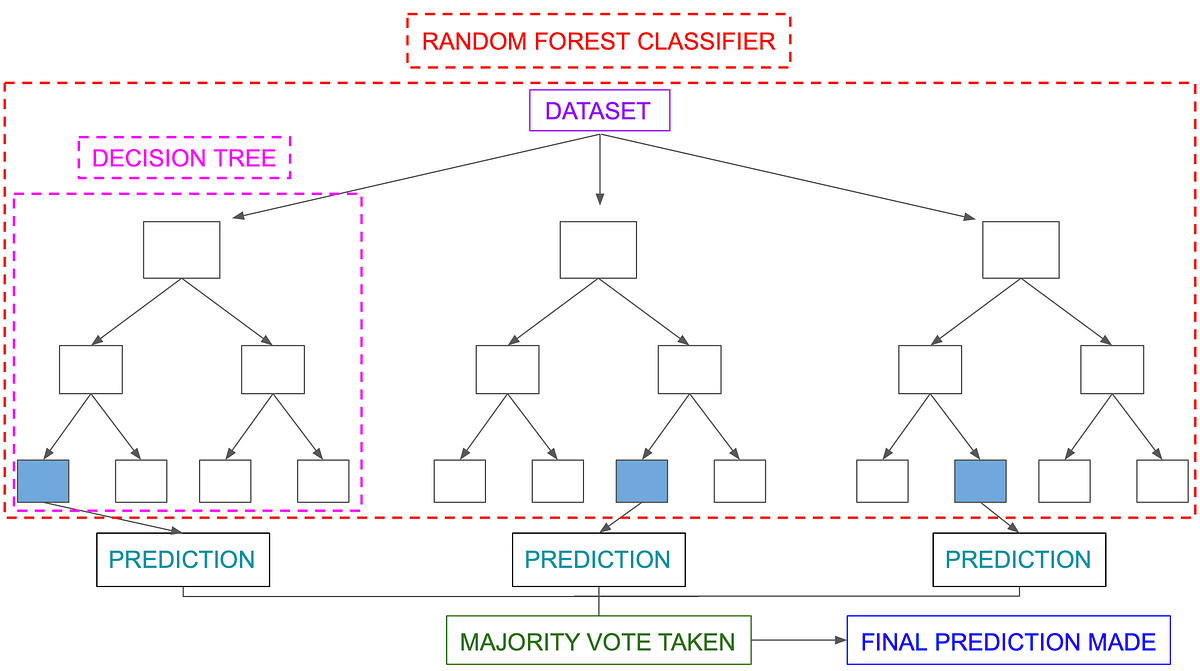
Random Forest is an ensemble method that combines multiple decision trees to classify, So the result of random forest is usually better than decision trees
Random forests is a supervised learning algorithm. It can be used both for classification and regression. It is also the most flexible and easy to use algorithm. A forest is comprised of trees. It is said that the more trees it has, the more robust a forest is. Random forests creates decision trees on randomly selected data samples, gets prediction from each tree and selects the best solution by means of voting. It also provides a pretty good indicator of the feature importance.
Random forests has a variety of applications, such as recommendation engines, image classification and feature selection. It can be used to classify loyal loan applicants, identify fraudulent activity and predict diseases. It lies at the base of the Boruta algorithm, which selects important features in a dataset.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv('Social_Network_Ads.csv')
df.describe()
df.shape
df.head(5)
# here purchased is our dependent variable
#Converting string values to int so that our model can fit to the dataset better
from sklearn.preprocessing import LabelEncoder
scall = LabelEncoder()
df.iloc[: , 1] = scall.fit_transform(df.iloc[:,1])
df.head(5)
# Splitting x and y here
x = df.iloc[: , 1:4].values
y = df.iloc[:, 4].values
print(x[:5])
# train test split
from sklearn.model_selection import train_test_split
x_train , x_test , y_train , y_test = train_test_split(x, y , train_size = 0.8, test_size = 0.2 , random_state = 1)
print(x_train.shape, x_test.shape , y_train.shape)
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier()
classifier.fit(x_train, y_train)
#predicting values
y_pred = classifier.predict(x_test)
from sklearn.metrics import accuracy_score, confusion_matrix
print('accuracy oy model is : ', accuracy_score(y_test, y_pred))
print('Confusion Matrix:','\n', confusion_matrix(y_test, y_pred))
## we have 86% accuracy in our model
## Out of all predictions 7+4 = 11 are incorrect prediction
plt.scatter(x_test[:, 1],y_test,color ='red')
plt.scatter(x_test[:,1],y_pred, color = 'blue')
plt.show()

We can clearly see the results the graph The values that are in a different color are predicted wrong rest are right